La question qu’on se pose ici est la suivante : comment approcher une fonction \(f : I \to \mathbb{R}\) par des fonctions simples, faciles à évaluer en un point par exemple. Le théorème d’approximation de Weierstrass affirme que toute fonction continue \(f\) peut être approchée par une suite de polynômes convergeant uniformément vers \(f\). La preuve de ce théorème n’étant pas constructive, dans ce qui suit nous tenterons, à l’aide de l’analyse numérique, d’approcher des fonctions réguliers par des polynômes (au moins par morceaux).
Interpolation de Lagrange
L’interpolation de Lagrange consiste à chercher un polynôme qui passe par un ensemble des points \((x_i, y_i)\). Si le valeurs \(y_i\) sont obtenues en évaluant une fonction \(f\) aux points \(x_i\), donc \(y_i = f(x_i)\), on parle d’un polynôme de Lagrange associé à la fonction \(f\) aux points \((x_i)\).
Soit \(n > 0\) un nombre entier et soient \((x_i)_{0 \le i \le n}\) nombres réels distincts. Soient \((y_i)_{0 \le i \le n}\) nombres réels. Il est facile à voir qu’il existe un unique polynôme \(P\) de degré au plus \(n\) tel que
\begin{equation}\tag{P} P(x_i) = y_i, \qquad 0 \le i \le n. \end{equation}
Pour déterminer le polynôme \(P\) satisfaisant les égalités (P) il suffit de considérer un polynôme \(P = \sum_{i = 0}^n a_i X^i\) et d’utiliser les relations (P) afin de déterminer les coefficients \(a_i\). En écrivant ces \(n + 1\) équations, on obtient le système linéaire suivant
\begin{equation} \left\{ \begin{array}{l} a_0 + a_1 x_0 + a_2 x_0^2 + \cdots + a_n x_0^n = y_0 \\ a_0 + a_1 x_1 + a_2 x_1^2 + \cdots + a_n x_1^n = y_1 \\ \vdots \\ a_0 + a_1 x_n + a_2 x_n^2 + \cdots + a_n x_n^n = y_n \\ \end{array} \right. \end{equation}
d’inconnues \(a_0,\ a_1,\ \dots, a_n\). Ce système s’écrit sous la forme matricielle \(M A = Y\), avec
\begin{equation} M = \begin{pmatrix} 1 & x_0 & x_0^2 & \cdots & x_0^n \\ 1 & x_1 & x_1^2 & \cdots & x_1^n \\ 1 & x_2 & x_2^2 & \cdots & x_2^n \\ \vdots & \vdots & \vdots & & \vdots \\ 1 & x_n & x_n^2 & \cdots & x_n^n \\ \end{pmatrix}, \qquad A = \begin{pmatrix} a_0 \\ a_1 \\ a_2 \\ \vdots \\ a_n \end{pmatrix},\qquad Y = \begin{pmatrix} y_0 \\ y_1 \\ y_2 \\ \vdots \\ y_n \end{pmatrix}. \end{equation}
Remarquer que la matrice \(M\) est une matrice de Vandermonde. Comme \((x_i)_{0 \le i \le n}\) sont distincts, cette matrice est inversible et donc la solution du système est unique ainsi que le polynôme \(P\). Cette démarche peut être mise en oeuvre rapidement:
import numpy as np
import matplotlib.pyplot as plt
import sympy as sp
sp.var("X") # declare la variable formelle X
def lagrange(x, y):
n = len(x) - 1
A = np.transpose(np.tile(x, (n + 1, 1)))
B = np.tile(range(0, n + 1), (n + 1, 1))
M = A ** B
a = np.linalg.solve(M, y)
P = a[0]
for i in range(1, n + 1):
P = P + a[i] * X ** i
return P
Nous allons utiliser la fonction lagrange pour calculer le
polynôme \(P\) associé à la fonction \(f : \mathbb{R} \to \mathbb{R}\),
\(f(x) = 2 \sin(\pi x) (x^2 + 1)\) aux points \(x_i = \frac{i}{2}\)
avec \(i \in \{-1, 0, 1, 3\}\).
def f(x):
return 2 * np.sin(np.pi * x) * (x ** 2 + 1)
x_fin = np.linspace(-2, 2.5, 1000)
plt.plot(x_fin, f(x_fin), color="red", label="$f$")
x = np.array([-0.5, 0, 0.5, 1.5])
y = f(x)
plt.plot(x, y, marker="o", color="black", linestyle="None",
label="$(x_i, y_i)$")
ax = plt.gca()
ax.set_xlim(-2, 2.5)
ax.set_ylim(-10, 20)
ax.grid(True)
plt.rc('text', usetex=True)
plt.rcParams['xtick.labelsize'] = 18
plt.rcParams['ytick.labelsize'] = 18
plt.title("$f(x) = 2 \sin(\pi x) (x^2 + 1)$", fontsize=18)
P = lagrange(x, y)
yP = [P.subs(X, c) for c in x_fin]
plt.plot(x_fin, yP, label="$P$")
plt.legend(loc=0, prop={'size': 18})
plt.show()
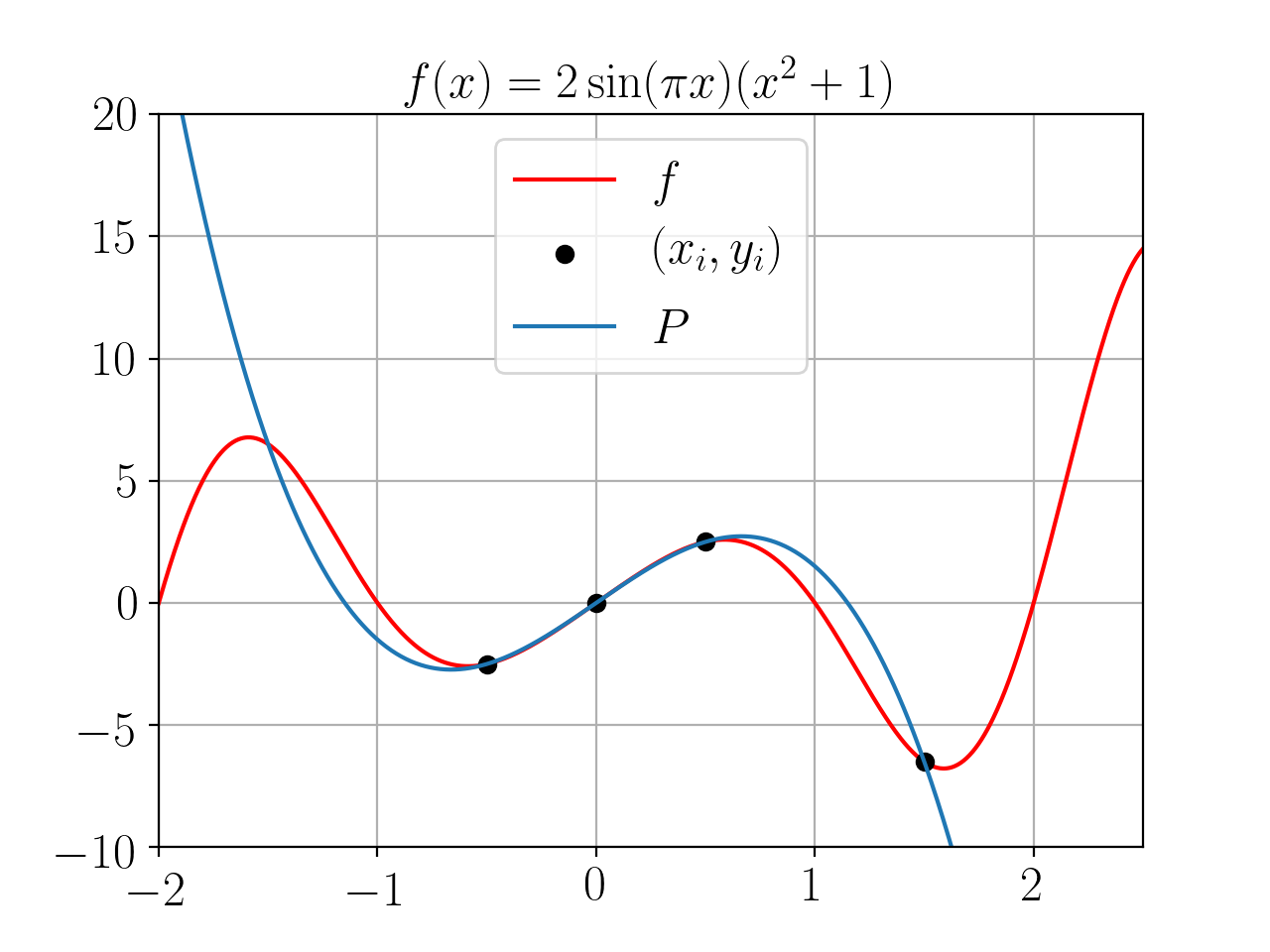
Figure 1: La fonction \(f(x) = 2 \sin(\pi x) (x^2 + 1)\) et son polynôme d’interpolation de Lagrange aux points \((x_i)_{0 \le i \le 4}\).
Pour la suite nous allons considérer \(f : [a, b] \to \mathbb{R}\) et \(x_0, \ x_1, \cdots, \ x_n\), \(n + 1\) points distincts dans l’intervalle \([a,b]\). On suppose de plus que les nombres \(x_i\) sont ordonnés : \[x_0 < x_1 < \cdots < x_n.\] Il s’agit donc de construire un polynôme \(P\) de degré inférieur à \(n\) tel que les égalité (P) soit vérifiées pour \(y_i = f(x_i)\).
On appelle ce polynôme un polynôme d’interpolation de Lagrange de la fonction \(f\) aux points \((x_i)_{0 \le i \le n}\). Ce polynôme sera également noté \(P_n\).
Théorème
Il existe un unique polynôme \(P_n\), de degré inférieur ou égal à \(n\), tel que \(P_n(x_i) = f(x_i)\) pour tout \(0 \le i \le n\).
Ce polynôme s’écrit \[P_n(x) = \sum_{i = 0}^{n} f(x_i)L_i(x)\] avec \(\displaystyle L_i(x) = \prod_{j = 0,\ j \neq i}^{n} \frac{x - x_j}{x_i - x_j}\).
Les polynômes \(\{L_0, \cdots, L_n\}\) forme une base de l’espace \(R^n[X]\) appelée la base de Lagrange.
Démonstration.
Il est facile à voir que pour tout \(i, j \in \{0, \cdots, n\}\) on a \[ L_i(x_j) = \delta_{ij} \] où
\begin{equation} \delta_{ij} = \left\{ \begin{array}{ll} 1,& \text{si } i = j \\ 0,& \text{sinon} \end{array} \right. \end{equation}
est le symbole de Kronecker. Alors, pour tout \(j \in \{0, \cdots, n\}\): \[P_n(x_j) = \sum_{i = 0}^n f(x_i) L_i(x_j) = \sum_{i = 0}^n f(x_i) \delta_{ij} = f(x_j),\] donc \(P_n\) est un polynôme d’interpolation de \(f\) aux point \((x_i)_{0 \le i \le n}\). En utilisant l’inversibilité de la matrice de Vandermonde associée aux système donné par les conditions d’interpolation aux points \(x_i\), ou encore, un raisonnement par absurde, on obtient l’unicité du polynôme d’interpolation de Lagrange.
La famille de polynômes \(\{L_0, \cdots, L_n\}\) est libre dans \(\mathbb{R}^n[X]\). Effectivement, soit \(a_0, \cdots, a_n\) tels que \[\sum_{i = 0}^n a_i L_i = 0.\] Soit \(j \in \{0, \cdots, n\}\). Alors \[\sum_{i = 0}^n a_i L_i(x_j) = 0\] et, donc, \(a_j = 0\). Comme la dimension de l’espace \(R^n[X]\) est \(n + 1\), il suit que \(\{L_0, \cdots, L_n\}\) est une base de cet espace.
Remarque
L’écriture du polynôme de Lagrange utilisant la base de polynômes de Lagrange \(\{L_0,\ \cdots,\ L_n \}\) est intéressante de point de vue théorique mais assez peu de point de vue pratique. En effet, si nous ajoutons un nouveau point d’interpolation aux point déjà existantes tous les polynômes de la base de Lagrange changent. Pour contourner ce problème on considère la base de Newton associée aux points distincts \(x_0,\ x_1,\ \cdots, x_n\):
\begin{equation} \left\{\mathcal{P}_0,\ \cdots,\ \mathcal{P}_n\right\}, \end{equation}
où \(\mathcal{P}_0(x) = 1\) et pour \(k \in \{1,\ \dots,\ n + 1\}\):
\begin{equation} \mathcal{P}_k(x) = \prod_{i=0}^{k - 1} (x - x_i). \end{equation}
Théorème
Le polynôme d’interpolation de Lagrange de la fonction \(f\) aux points distincts \((x_i)_{0 \le i \le n}\) est donné par
\begin{equation} P_n(x) = \sum_{i = 0}^n f[x_0, \dots, x_i]\mathcal{P}_i(x), \end{equation}
où \(f[\ ]\) désigne les différences divisées de \(f\) définies par \(f[x_i] = f(x_i)\) pour \(i \in \{0, \dots, n\}\) et
\begin{equation} f[x_k, \dots, x_\ell] = \frac{f[x_{k + 1}, \dots x_\ell] - f[x_k, \dots, x_{\ell - 1}]}{x_\ell - x_k}, \end{equation}
pour tout \(0 \le k < \ell \le n\).
Démonstration.
Nous démontrons ce théorème par récurrence sur le nombre de points d’interpolation. Pour tout \(k \in \{0, 1, \cdots, n\}\) on note \(\mathbb{P}(k)\) énoncé suivant:
\begin{equation}\label{eq:Pk}\tag{$\mathbb{P}(k)$} P_k(x) = \sum_{i = 0}^k f[x_0, \dots, x_i]\mathcal{P}_i(x), \end{equation}
où \(P_k\) est le polynôme d’interpolation de Lagrange de la fonction \(f\) aux points \(x_0,\cdots, x_k\).
Il est évident que \((\mathbb{P}(0))\) est vrai.
Soit \(k \in \{0, \cdots, n-1\}\) est supposons que \eqref{eq:Pk} est vrai. On cherche \(P_{k + 1}\) sous la forme \(P_{k + 1}(x) = P_k(x) + a \mathcal{P}_{k+1}(x)\).
Soit \(Q_{k}\) le polynôme d’interpolation de Lagrange de \(f\) aux points \(x_1, \cdots, x_{k+1}\). A l’aide de l’hypothèse de récurrence, on a que
\begin{equation} Q_{k}(x) = \sum_{i = 1}^{k+1} f[x_1, \cdots, x_i] \prod_{j = 1}^{i - 1}(x - x_j). \end{equation}
On note \(Q \in \mathbb{R}^{k+1}[x]\) le polynôme défini par \[\displaystyle Q(x) = \frac{x - x_0}{x_{k + 1} - x_0} Q_k(x) + \frac{x_{k + 1} - x}{x_{k + 1} - x_0} P_k(x).\] Ce polynôme \(Q\) est construit de manière que
\begin{align*} Q(x_0) & = P_k(x_0) = f(x_0) \\ Q(x_i) & = \frac{x_i - x_0}{x_{k + 1} - x_0} Q_k(x_i) + \frac{x_{k + 1} - x_i}{x_{k + 1} - x_0} P_k(x_i) \\ & = \left(\frac{x_i - x_0}{x_{k + 1} - x_0} + \frac{x_{k + 1} - x_i}{x_{k + 1} - x_0}\right) f(x_i) \\ & = f(x_i), \quad \text{si } 1 \le i \le k \\ Q(x_{k+1}) & = Q_k(x_{k + 1}) = f(x_{k + 1}), \end{align*}
donc \(Q\) n’est rien d’autre que le polynôme \(P_{k + 1}\) d’interpolation de Lagrange de \(f\) aux points \(x_0,\ \cdots, x_{k + 1}\). En identifiant le coefficient du terme \(x^{k + 1}\) dans les deux polynômes on obtient \[ a = \frac{f[x_1,\ \cdots,\ x_{k + 1}] - f[x_0,\ \cdots,\ x_k]}{x_{k+1} - x_0} = f[x_0,\ \cdots,\ x_{k + 1}], \] donc \(\mathbb{P}(k + 1)\) est vrai. Par une récurrence finie on obtient la conclusion du théorème.
Remarque
Le calcul des différences divisées est fait en pratique par l’algorithme suivant:
Initialisation :
Calculer les différences divisées d’ordre \(1\)
\(\qquad\) \(f[x_k] = f(x_k)\) pour \(0 \le k \le n\)
Pour \(i = 1, \dots, n\)
\(\qquad\) Calculer les différences divisées d’ordre \(i + 1\)
\(\qquad\) Pour \(k = 0, \dots, n - i\)
\(\qquad\qquad\) \(\small \displaystyle f[x_k, \dots x_{k + i}]=\frac{f[x_{k + 1}, \dots, x_{k + i}] - f[x_k, \dots, x_{k + i - 1}]}{x_{k + i} - x_k}\)
\(\qquad\) Fin
Fin
Théorème (étude de l’erreur)
Soit \(f : [a, b] \to \mathbb{R}\). Supposons que \(f\) est de classe \(\mathcal{C}^{n + 1}\) et que \(P_n\) est le polynôme de Lagrange de \(f\) défini aux points distincts \((x_i)_{0 \le i \le n}\) de \([a, b]\). Alors
\begin{equation} | P_n(x) - f(x) | \le \frac{\sup_{x \in [a, b]} |f^{(n + 1)}(x)|}{(n + 1)!} | \mathcal{P}_{n+1}(x) |. \end{equation}
La preuve de ce théorème est en grande partie basée sur le lemme suivant:
Lemme (généralisation des accroissements finis)
Soit \(f : [a, b] \to \mathbb{R}\) de classe \(\mathcal{C}^p\). Alors, il existe \(\xi \in [a, b]\) tel que \[f[x_0, \dots, x_p] = \frac{f^{(p)}(\xi)}{p!}\]
Preuve du lemme
Soit \(g : [a, b] \to \mathbb{R}\) définie par \(g(x) = f(x) - P_p(x)\) où \(P_p\) est le polynôme de Lagrange de \(f\) aux points \(x_0,\ \cdots,\ x_p\). Alors \(g \in C^p([a, b])\) et \(g(x_i) = 0\) pour \(i \in \{0, \cdots, p\}\). Appliquant \(p\) fois le théorème de Rolle, il existent \(x_0^{1},\ \cdots,\ x_{p-1}^1\) distincts dans \([a, b]\) tels que \(g’(x_i^1) = 0\) pour \(0 \le i \le p-1\). On applique maintenant \(p - 1\) fois le théorème de Rolle pour la fonction \(g’\): il existent \(x_0^2,\ \cdots,\ x_{p-2}^2\) distincts dans \([a, b]\) tels que pour tout \(0 \le i \le p-2\) on a \(g^″(x_i^2) = 0\). On applique toujours \(p - 2\) fois le théorème de Rolle pour \(g^″\) et ainsi du suite. Finalement, après \(p(p + 1)/2\) applications du théorème de Rolle, il existe \(\xi \in [a, b]\) tel que \(g^{(p)}(\xi) = 0\). En tenant compte que \(P_p \in \mathbb{R}^p[x]\) est le polynôme de Lagrange de \(f\) aux points \(x_0,\ \cdots,\ x_p\), donc avec un résultat précédent \[P(p)(x) = \sum_{i=0}^p f[x_0,\ \cdots,\ x_i] \mathcal{P}_i(x),\] on a que \(P_p^{p}(x) = p! f[x_0,\ \cdots,\ x_p]\), donc \(g^{(p)}(\xi) = 0\) implique la conclusion du lemme.
Démonstration du théorème
Soit \(x \in [a, b]\), \(x \ne x_i\) et soit \(Q \in \mathbb{R}^{n + 1}[z]\) le polynôme d’interpolation de \(f\) aux points \(x_0, \dots, x_n\) et \(x\).
D’après la formule de Newton, \[Q(z) = P_n(z) + f[x_0, \dots, x_n, x]\mathcal{P}_{n + 1}(z).\] En appliquant le lemme précédent, il existe \(\xi \in [a, b]\) tel que \[Q(z) = P_n(z) + \frac{f^{(n + 1)}(\xi)}{(n + 1)!}\mathcal{P}_{n + 1}(z).\] En tenant compte du fait que \(Q(x) = f(x)\), on obtient la conclusion du théorème.
Remarque
L’estimation d’erreur du théorème ne donne pas la convergence uniforme de \(P_n\) vers \(f\) quand \(n \to +\infty\). En fait, plus \(n\) est grand, plus le polynôme d’interpolation \(P_n\) oscille rapidement entre les points d’interpolation \((x_i)_{0 \le i \le n}\) (supposés équidistribués dans l’intervalle \([a, b]\)). Ce phénomène est connu sous le nom de phénomène de Runge.
Pour éviter le phénomène de Runge, une stratégie possible est l’interpolation composée, ou l’interpolation par des polynômes par morceaux.
Interpolation d’Hermite
L’objectif de l’interpolation d’Hermite est de construire un polynôme d’interpolation d’une fonction \(f : [a, b] \to \mathbb{R}\) de classe \(C^1\) en utilisant les valeurs de \(f\) et de sa dérivée aux points \((x_i)_{0 \le i \le n}\) de l’intervalle \([a, b]\). Il s’agit donc de trouver un polynôme \(P_n\) de degré minimal qui vérifie
\begin{equation} P_n(x_i) = f(x_i), \quad P_n’(x_i) = f’(x_i), \quad 0 \le i \le n. \end{equation}
On peut démontrer le résultat suivant.
Théorème (étude de l’erreur)
Le polynôme \(P_n\) est de degré au plus \((2n + 1)\) et s’écrit
\begin{equation} P_n(x) = \sum_{i = 0}^n f(x_i) H_i(x) + \sum_{i = 0}^n f’(x_i) \tilde H_i(x) \end{equation}
avec \(H_i(x) = (1 - 2 L_i’(x_i)(x - x_i))L_i^2(x)\) et \(\tilde H_i(x) = (x - x_i)L_i^2(x)\).
De plus, si \(f \in \mathcal{C^{2n + 2}}([a, b], \mathbb{R})\)
\begin{equation} |f(x) - P_n(x)| \le \frac{\|f^{(2n + 2)}\|_\infty}{(2n + 2)!} \left| \mathcal{P}_{n+1}(x) \right|^2. \end{equation}
Le polynôme \(P_n\) est unique et il s’appelle le polynôme d’interpolation d’Hermite de la fonction \(f\).
Exemple : splines cubiques
Soit \(f\) une fonction dérivable sur l’intervalle \([0, 1]\). Le polynôme
\begin{equation} P(x) = f(0) p_0(x) + f(1) p_1(x) + f’(0) \tilde{p}_0(x) + f’(1) \tilde{p}_1(x) \end{equation}
avec
\begin{equation} \left\{ \begin{array}{l} p_{0}(x) = 2x^3 - 3x^2 + 1 \\ \tilde{p}_{0}(x) = x^3 - 2x^2 +x \\ p_{1}(x) = -2x^3 + 3x^2 \\ \tilde{p}_{1}(x) = x^3 - x^2, \end{array} \right. \end{equation}
vérifie
\begin{equation} P(0) = f(0),\ P(1) = f(1),\ P’(0) = f’(0),\ P’(1) = f’(1). \end{equation}
Le petit code python suivant calcul donc les splines cubiques \(p_0,\ p_1,\ \tilde{p}_0,\ \tilde{p}_1\):
import sympy as sp
import sympy.solvers.solvers
import numpy as np
sp.var('X a0 a1 a2 a3')
P = a0 + a1 * X + a2 * X**2 + a3 * X**3
dP = sp.diff(P, X)
A = np.eye(4, dtype=int)
print('Les splines cubiques:\n')
for i in range(4):
E1 = P.subs(X, 0) - A[i, 0]
E2 = dP.subs(X, 0) - A[i, 1]
E3 = P.subs(X, 1) - A[i, 2]
E4 = dP.subs(X, 1) - A[i, 3]
S = sympy.solvers.solve([E1, E2, E3, E4], a0, a1, a2, a3)
PP = S[a0] + S[a1] * X + S[a2] * X**2 + S[a3] * X**3
sp.pprint(PP)
Les splines cubiques:
3 2
2⋅X - 3⋅X + 1
3 2
X - 2⋅X + X
3 2
- 2⋅X + 3⋅X
3 2
X - X
Méthode des moindres carrés
La méthode des moindres carrés peut être décrite comme suit. Soient
- \((x_i)_{0 \le i \le n} \subset \mathbb{R}\)
- \((y_i)_{0 \le i \le n} \subset \mathbb{R}\)
- \(0 \le m \le n\)
- \(\phi_j : \mathbb{R} \to \mathbb{R}\) pour \(0 \le j \le m\)
et \[ \mathcal{U} = \text{Vect}\{\phi_0, \dots, \phi_m\}. \]
On cherche \(\phi^\star \in \mathcal{U}\) telle que
\[\sum_{i = 0}^n |y_i - \phi^\star(x_i)|^2 = \min_{\phi \in \mathcal{U}} \sum_{i = 0}^n |y_i - \phi(x_i)|^2.\]
On peut démontrer le résultat suivant:
Théorème
Soit \((\phi_j)_{0 \le j \le m}\) une famille libre de polynômes. Alors il existe une unique fonction \(\phi^\star \in \mathcal{U}\) solution de
\begin{equation} \sum_{i = 0}^n |y_i - \phi^\star(x_i)|^2 = \min_{\phi \in \mathcal{U}} \sum_{i = 0}^n |y_i - \phi(x_i)|^2. \end{equation}
De plus, \(\phi^\star(x) = \sum\limits_{j = 0}^m u_j^\star \phi_j(x)\) où \(\boldsymbol{u}^\star = \left( u_0^\star,\, \dots,\, u_m^\star \right)^T \in \mathbb{R}^{m+1}\) est l’unique solution du système linéaire \[ B^T B\boldsymbol{u}^\star = B^T \boldsymbol{y},\] avec \(\boldsymbol{y} = \left( y_0,\, \dots,\, y_n\right)^T \in \mathbb{R}^{n+1}\) et \(B \in \mathcal{M}_{n + 1, m + 1}(\mathbb{R})\) donnée par
\begin{equation} B = \begin{pmatrix} \phi_0(x_0) & \dots & \phi_m(x_0) \\ \vdots & & \vdots \\ \phi_0(x_n) & \dots & \phi_m(x_n) \end{pmatrix}. \end{equation}
Démonstration.
Pour tout \(\phi \in \mathcal{U}\) il existe un unique \(\boldsymbol{u} = \begin{pmatrix}u_0& \cdots & u_m \end{pmatrix}^T \in \mathbb{R}^{m + 1}\) tel que \[ \phi(x) = \sum_{j = 0}^m u_j \phi_j(x). \] Alors,
\[ \sum_{i = 0}^n |y_i - \phi(x_i)|^2 = \sum_{i = 0}^n |y_i - \sum_{j = 0}^m u_j \phi_j(x_i)|^2 = \|\boldsymbol{y} - B \boldsymbol{u}\|_2^2. \]
Le problème de minimisation du théorème n’est rien que le problème de minimisation suivant: trouver \(\boldsymbol{u} \in \mathcal{R}^{m + 1}\) solution de
\[ \min_{\boldsymbol{u} \in \mathbb{R}^{m + 1}} \|y - B\boldsymbol{u}\|_2^2. \]
L’unique solution de cet problème de minimisation vérifie \(B^TB \boldsymbol{u}^\star = B^T\boldsymbol{y}\) (voir [1] pour une preuve).
Les preuves de certains des résultats énoncés plus haut suivront sous peu. En attendant, vous pouvez consulter les livres [2, 3] dont la présentation est en grand partie inspirée.
Biblio
- Ciarlet, Philippe G. Introduction à l’analyse numérique matricielle et à l’optimisation. 1982.
- Demailly, Jean-Pierre. Analyse numérique et équations différentielles-4ème Ed. EDP sciences, 2016.
- Filbet, Francis. Analyse numérique-Algorithme et étude mathématique-2e édition: Cours et exercices corrigés. Dunod, 2013.