L’analyse numérique propose des méthodes pour l’étude des problèmes mathématiques à l’aide des ordinateurs et donc des algorithmes. Un des objectifs principaux de l’analyse numérique est de discuter les conséquences de l’implémentation numérique.
L’objet central de l’analyse numérique est l’étude des erreurs, leur sources, ainsi que leur propagation et leur analyse.
Les erreurs que nous allons considérer sont de deux types: erreurs relatives et erreurs absolues. Si \(x\) est une quantité exacte (supposée non-nulle) et \(x_{\text{approx}}\) une quantité approchant la quantité \(x\), on définit l’erreur absolue \(e\) par \[ e = \vert x - x_\text{approx}\vert \] et l’erreur relative \(e_\text{rel}\) comme suit: \[e_\text{rel} = \frac{\vert x - x_\text{approx}\vert}{\vert x\vert}.\]
Exemple
Une distance de \(10m\) est mesurée à l’aide d’un mètre à ruban et on trouve une mesure de \(10m\) et \(3cm\): \(x = 10\) et \(x_\text{approx}=10.03\). Alors, l’erreur relative est \(0.003\) et l’erreur absolue est de \(0.03\).
Par contre, si on fait une erreur de \(3cm\) pour mesurer la taille d’un objet de \(1cm\), l’erreur relative est de \(3\), ce qui n’est pas du tout acceptable.
Les nombres vus par l’ordinateur – \(\mathbb{N} \subset \mathbb{Z} \subset \mathbb{Q} \subset \mathbb{R}\)
Si les nombres entiers (inférieurs à un seuil défini par le type utilisé) peuvent être représentés de manière exacte par l’ordinateur, les nombre réels sont représentés de manière approchée. De manière générale, tout nombre réel \(x\) peut être écrit sous la forme suivante: \[ x = \color{green}{\sigma} \cdot (. \color{green}{a_1 a_2 \dots a_t} a_{t+1} \dots)_\beta \cdot \beta^{\color{green}{e}}, \] où:
- \(\beta \in \mathbb{N}\), \(\beta \ge 2\) est la base;
- \({\color{green} \sigma} \in \{\pm 1\}\) est le signe de \(x\);
- \((.\color{green}{a_1 a_2 \dots a_t} a_{t+1} \dots)_\beta \in [0, 1)\) est la mantisse;
- \(\color{green}{e} \in \mathbb{Z}\).
Une autre façon de voir la formule précédente est: \[x = \color{green}{\sigma} \beta^{\color{green}{e}} \sum_{n = 1}^{+ \infty} \color{green}{a_n} \beta^{-n} \]
Comme les ordinateurs utilisent une quantité de mémoire finie pour représenter un nombre, le nombre de chiffres décimales de la mantisse ainsi que l’exposant sont finis. On suppose donc qu’on utilise \(\color{green}{t}\) chiffres pour la mantisse et que \(\color{green}{L \le e \le U}\).
Si la base dans laquelle on représente les nombres est choisie a priori (2, 10, 16, etc.), les nombres \({\color{green}t}\), \({\color{green}L}\) et \({\color{green} U}\) ont beaucoup varié d’un ordinateur à l’autre le long de l’histoire de l’ordinateur. La Figure du livre [1] donne l’état de l’art de l’année 1989.
![Figure 1: Représentation des réels par différentes ordinateurs [Atkinson]](https://lmbp.uca.fr/~cindea/blog/ox-hugo/atkinson.png)
Figure 1: Représentation des réels par différentes ordinateurs [Atkinson]
La grande majorité des ordinateurs d’aujourd’hui implémente le standard IEEE754, avec sa dernière révision datant de 2008.
![Figure 2: IEEE Standard for Floating-Point Arithmetic [2]](https://lmbp.uca.fr/~cindea/blog/ox-hugo/ieee754.png)
Figure 2: IEEE Standard for Floating-Point Arithmetic [2]
Ce standard donne des règles pour les calculs en virgule flottante, de manière que les résultats soit indépendants de l’ordinateur ou du logiciel utilisé:
- plusieurs types de nombres en virgule flottante (simple et double précision)
- ensemble des nombres représentables
- encodages des nombres
- opérations élémentaires
- fonctions élémentaires
- traitement des erreurs (exceptions).
Par exemple, les nombre réels utilisés par défaut par la plupart
de langage de programmation (dont python) sont en double
précision: on utilise 64 bits pour représenter un nombre:
- 1 bit de signe
- 11 bits d’exposant (−1022 à 1023)
- 52 bits de mantisse.
Malgré ces efforts de standardisation, différents langages
informatiques peuvent donner différents résultats pour une
opération si simple que \(0.1 + 0.2\). Le site
http://0.30000000000000004.com/ recense la réponse d’une
soixantaine de langages quand on demande d’afficher \(0.1 + 0.2\).
En général, ces différences sont la conséquence d’utilisation de
différents types pour représenter 0.1 et 0.2, ou encore, du
style d’affichage des nombres qui diffère d’un langage à autre.
Voici un exemple de programme python pour calculer \(0.1 + 0.2\)
et afficher le résultat.
a = 0.1
b = 0.2
c = a + b
print(c)
if c == 0.3:
print("0.1 + 0.2 = 0.3...")
else:
print("0.1 + 0.2 != 0.3...")
0.30000000000000004
0.1 + 0.2 != 0.3...
Remarquer que \(0.1 + 0.2 \ne 0.3\) pour une comparaison triviale à
l’aide de la commande if de python. Il faut donc rester
vigilants dès qu’on compare des nombres réels. Savez-vous expliquer le programme python suivant?
# un calcul avec des entiers
print(10**16 - 221349167 * 45177491)
# le même calcul avec des réels
print(10.0**16 - 221349167 * 45177491)
# quel est le bon résultat ?
3
4.0
Le même phénomène apparaît, de manière plus claire, dans le programme suivant:
i = 0
while 0 != 2**(-i):
i += 1
print("Dernière valeure de i t.q. 0 != 2**(-i) est : ", i - 1)
Dernière valeure de i t.q. 0 != 2**(-i) est : 1074
Comment explique t-on le nombre \(1074\) obtenu par le programme précédent?
Les sources des erreurs
Quand on résout un problème à l’aide d’un ordinateur les sources des erreurs sont multiples. Les erreurs les plus fréquentes sont:
- erreurs de modélisation
- erreurs de calcul ou les bugs informatiques
- erreurs d’arrondi
- erreurs de mesure
- erreurs de troncature mathématique.
Erreurs dues à la modélisation mathématique
Les erreurs de modélisation sont dues aux hypothèses qu’on suppose vérifiées par une situation en vue de la décrire par des objets mathématiques.
Voici un exemple simple de modélisation de l’offre et de la demande dans un marché.
Exemple : analyse de l’offre et de la demande
Imaginons la situation suivante:
- \(n\) artisans fabriquant \(n\) produits
- afin d’éviter le coût de stockage des produits fabriqués, nous recherchons une situation d’équilibre entre l’offre et la demande.
- les artisans ont décidé de coopérer, donc ils souhaite adapter
leur production:
- à leur propres besoins déterminés par la quantité de produit nécessaires aux autres artisans pour qu’il puisse fabriquer leur propre produit
- aux besoins du marché.
Notations :
- \(i \in \{1, 2, \dots, n\}\): le produit fabriqué par un artisan \(i\)
- \(\color{red}{x_i}\): la quantité de produit \(i\) fabriquée
- \(b_i\): la demande du marché en produit \(i\)
- \((c_{i,j})_{1 \le i, j \le n}\): la quantité de produit \(i\) nécessaire à la fabrication d’une unité de produit \(j\).
Trouver \(\color{red}{x = (x_1, x_2, \dots, x_n)}\) solution de: \[\color{red}{x_i} = \sum_{j = 1}^n c_{i, j} \color{red}{x_j} + b_i, \qquad i = 1, 2, \dots, n\] ou encore \[ \color{red}{x} = C\color{red}{x} + b. \]
Modélisation :
- la relation qui lie différents produits est linéaire
- la demande du marché est connue
- chaque artisan fabrique un seul produit…
Chaque hypothèse influence les résultats et peut être source d’erreurs.
Plusieurs difficultés mathématiques:
- quelles sont les propriétés de la matrice \(A = I_n - C\) permettant d’assurer que ce problème à bien une solution (positive)?
- quand \(n\) est grand, en pratique il est difficile d’inverser la matrice \(A\), donc il faudra trouver des algorithmes ne nécessitant pas son inversion.
Erreurs de calcul - bugs informatiques
Avant l’ordinateur, les erreurs de calcul étaient des erreurs d’arithmétique. Actuellement, on pourra penser qu’avec les ordinateurs ces erreur ont disparu. En effet, elle ont été remplacées par les erreurs de programmation : bugs.
Une question qu’on essayera de répondre est la suivante : comment faire pour trouver les erreurs?
Erreurs dues à la précision de la machine ou erreurs d’arrondi
Les erreurs d’arrondi sont dues à la représentation des nombres réels en virgule flottante en utilisant un nombre fini de chiffres ou, encore, à la longueur finie de la mantisse.
Erreurs de mesure
La plupart des données expérimentales sont incertaines. Ceci a un effet sur les calculs utilisant ces données et la précision des résultats. On traite les erreurs de mesure d’une manière similaire aux erreurs d’arrondi.
Erreurs de troncature mathématique
Ce type d’erreur se réfère à l’approximation utilisée pour la résolution numérique d’un problème mathématique et, en général, est associé à l’analyse numérique.
On remplace une quantité infinie par des quantités finies.
Quelques exemples d’erreur de troncature
-
on remplace une fonction par son D.L.
\begin{equation} \sqrt{1 + x} \approx 1 + \frac{x}{2}\quad \text{ou} \quad \sqrt{1 + x} \approx 1 + \frac{x}{2} - \frac{x^2}{8} \end{equation}

Figure 3: Une fonction et ses D.L. à l’ordres 1 et 2.
-
on approche une intégrale par une somme
\[\int_0^1 f(x) dx \approx \frac{1}{n} \sum_{j = 1}^n f\left( \frac{2j - 1}{2n}\right).\]
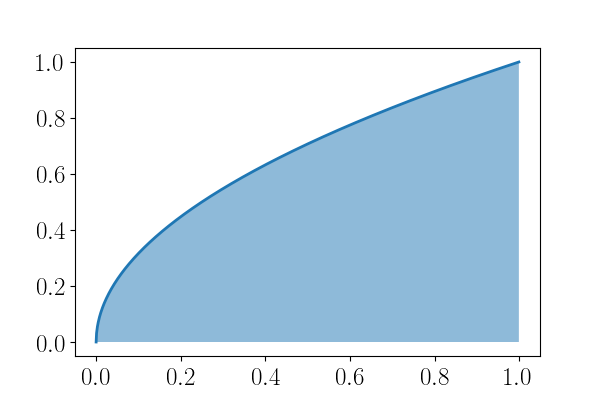
Figure 4: \(\displaystyle \int_0^1 \sqrt{x} dx\)
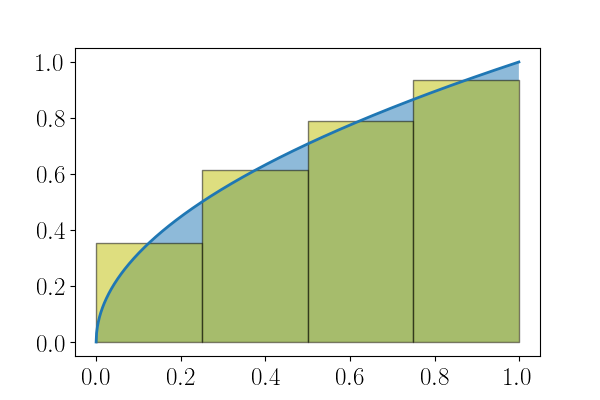
Figure 5: \(\displaystyle \int_0^1 \sqrt{x} dx\) et approximation avec \(n = 4\).
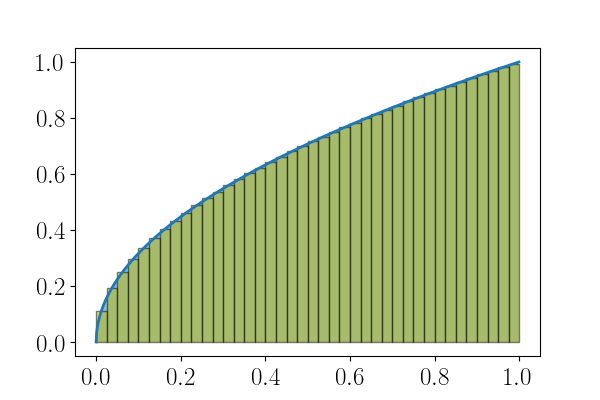
Figure 6: \(\displaystyle \int_0^1 \sqrt{x} dx\) et approximation avec \(n = 40\).
-
on remplace un test d’égalité par une inégalité
\[\color{red}{f(x) = 0 \qquad \text{vs.} \qquad |f(x)| < \varepsilon}\]

Figure 7: Graphe de \(\\ f(x) = (x - 1)^3\) et zoom autour de \(1\).
Quelles erreurs étudie l’analyse numérique?
L’analyse numérique est centrée sur l’étude des erreurs de troncature.
L’exception sera la partie sur la résolution de systèmes linéaires où l’arrondi sera la source la plus importante d’erreurs.
Propagation de l’erreur d’arrondi et perte de signification
Soit \(x\) un réel et \(x_\varepsilon\) sa représentation machine: \[x_\varepsilon = x + \varepsilon.\]
Soit \(f\) une fonction mathématique appliquée à \(x\) et \(\widetilde f\) l’opération équivalente faite par ordinateur.
On se propose d’évaluer \[E = \color{red}{|\widetilde f(x_\varepsilon) - f(x) | \le \dots}.\]
Si l’erreur \(E\) est grande on parle d’une perte de signification.
Considérons l’exemple du calcul de l’intégrale \[f(x) = \int_0^1 e^{xt} dt = \frac{e^x - 1}{x}, \text{ si } x \ne 0\] et évaluons la fonction \(f(x)\) pour des valeurs de \(x\) proches de \(0\). Avant cela, remarquons que \(f(0) = 1\) et \(f\) est continue sur \(\mathbb{R}\).
Le programme suivant permet d’illustrer une perte de signification quand \(x \to 0\)
import math
def f(x):
return (math.exp(x) - 1) / x
for i in range(20):
x = 10**(-i)
print('f({0:.20f}) = {1:.20f}'.format(x, f(x)))
f(1.00000000000000000000) = 1.71828182845904509080
f(0.10000000000000000555) = 1.05170918075647712442
f(0.01000000000000000021) = 1.00501670841679491275
f(0.00100000000000000002) = 1.00050016670838459731
f(0.00010000000000000000) = 1.00005000166714097531
f(0.00001000000000000000) = 1.00000500000696490588
f(0.00000100000000000000) = 1.00000049996218365322
f(0.00000010000000000000) = 1.00000004943368026034
f(0.00000001000000000000) = 0.99999999392252902908
f(0.00000000100000000000) = 1.00000008274037099909
f(0.00000000010000000000) = 1.00000008274037099909
f(0.00000000001000000000) = 1.00000008274037099909
f(0.00000000000100000000) = 1.00008890058234101161
f(0.00000000000010000000) = 0.99920072216264088638
f(0.00000000000001000000) = 0.99920072216264088638
f(0.00000000000000100000) = 1.11022302462515654042
f(0.00000000000000010000) = 0.00000000000000000000
f(0.00000000000000001000) = 0.00000000000000000000
f(0.00000000000000000100) = 0.00000000000000000000
f(0.00000000000000000010) = 0.00000000000000000000
Comment éviter cette perte de signification?
Stabilité et conditionnement
Un grand nombre de problèmes mathématiques ont des solutions assez sensibles aux erreurs de calcul, par exemple, aux erreurs d’arrondi.
Pour quantifier cette sensibilité, on introduit deux concepts:
- stabilité
- conditionnement.
L’illustration de ces deux concepts sera limitée aux problèmes de type suivant:
\begin{equation} \tag{P} \left\{ \begin{array}{l} \text{Pour } \color{blue}{y} \text{ et } F \text{ donnés}\\ \text{trouver } \color{red}{x} \text{ tel que } F(\color{red}{x}, \color{blue}{y}) = 0. \end{array} \right. \label{P} \end{equation}
Stabilité
On dit que (P) est stable si la solution \(\color{red}{x}\) dépend de manière continue de \(\color{blue}{y}\).
Autrement dit, si \(\color{blue}{y_n \to y}\) alors \(\color{red}{x_n \to x}\), où
- \(\color{red}{x_n}\) est la solution de (P) associée à \(\color{blue}{y_n}\)
- \(\color{red}{x}\) est la solution de (P) associée à \(\color{blue}{y}\).
Exemple: calculer la plus grand solution de l’équation \(x^2 + 2x + \color{blue}{y_n} = 0\) avec \[\color{blue}{y_n} \le 1 \text{ et } \color{blue}{y_n} \to y = 1.\]
Bien évidement, \(\displaystyle \color{red}{x_n} = -1 + \sqrt{1 - \color{red}{y_n}}\), \(\displaystyle \color{red}{x} = -1 + \sqrt{1 - \color{red}{y}}\) et \(x_n \to x\) quand \(y_n \to y, y_n \le y\).
Le calcul de \(x_n\) est stable par rapport à \(y_n\).
Un problème beaucoup moins stable est le calcul des racines du polynôme \[w_y(x) = \prod_{i = 1}^{10} (x - i) - \color{blue}{y} * x^{-9}.\]
Si \(\color{blue}{y} = 0\) alors les racines de \(w_0\) sont les nombres entiers \(\{1, 2, \cdots, 10\}\). Pour des valeur assez petites de \(\color{blue}{y}\) les racines du polynôme \(w_{\color{blue}{y}}\) changent de manière assez importante. Dès que \(\color{y} \ne 0\) il faudra approcher numériquement les racines du polynôme.
Le programme python suivant calcule numériquement les racines
du polynôme \(w_{\color{blue}{y = 2^{-10}}}\):
import sympy as sp
import matplotlib.pyplot as plt
x = sp.Symbol('x')
w = 1
for i in range(1, 11):
w *= (x - i)
rw = sp.solvers.solve(w, x)
rtildew = sp.solvers.solve(w - 2**-10 * x**9, x)
x0, y0 = [], []
x, y = [], []
for i in range(10):
print(rw[i], '---', rtildew[i])
x0.append(sp.re(rw[i]))
y0.append(sp.im(rw[i]))
x.append(sp.re(rtildew[i]))
y.append(sp.im(rtildew[i]))
plt.plot(x0, y0, 's')
plt.plot(x, y, 'o')
plt.xlabel('$\Re(x_i)$')
plt.ylabel('$\Im(x_i)$')
plt.legend(['$y = 0$', '$y = 2^{-10}$'])
plt.show()
1 --- 0.999999997308856
2 --- 2.00001240174994
3 --- 2.99810779247938
4 --- 4.07364780822175
5 --- 4.62313524990196
6 --- 10.8002132787522
7 --- 6.05020808274269 - 1.12654408936039*I
8 --- 6.05020808274269 + 1.12654408936039*I
9 --- 8.70272193430027 - 1.67935115881105*I
10 --- 8.70272193430027 + 1.67935115881105*I
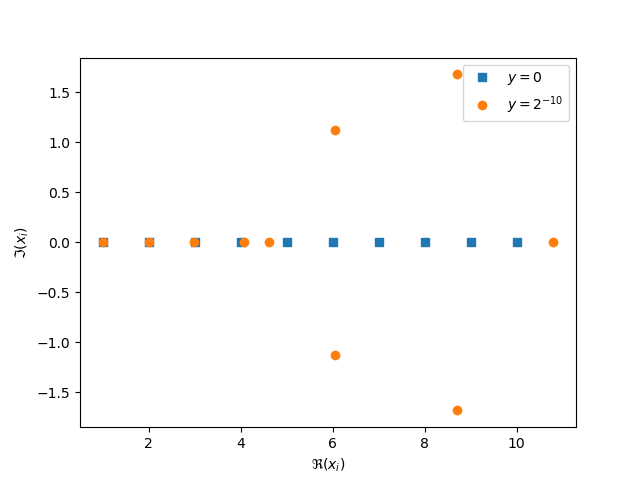
Figure 8: Racines des polynômes \(w_y\) pour \(y = 0\) et \(y = 2^{-10}\).
Cet exemple est connu sous le nom d’exemple de Wilkinson [3].
Conditionnement
Le conditionnement d’un problème donne une mesure plus précise que la stabilité de la dépendance de la solution d’un problème par rapport au paramètre du problème. Plus précisément, donne une information sur le contrôle de l’erreur relative sur la solution \(\color{red}{\frac{\|\delta_x\|}{\|x\|}}\) en fonction de l’erreur relative sur le paramètre \(\color{blue}{\frac{\|\delta_y\|}{\|y\|}}\).
Soit \(\color{red}{x \neq 0}\) la solution de (P) associée à \(\color{blue}{y}\) et soit \(\color{red}{x + \delta_x}\) la solution de (P) associée à \(\color{blue}{y + \delta_y}\) avec \(\delta_y\) tel que \[0 < \|\delta_y\| < \Delta_y \text{ pour } \Delta_y \text{ fixé.}\]
On appelle le conditionnement du problème (P) la quantité \(K\) définie par:
\[\color{magenta}{K = \sup_{0 < \|\delta_y\| < \Delta_y} \frac{\|\delta_x\|}{\|x\|} \frac{\|y\|}{\|\delta_y\|}.}\]
Biblio
-
ATKINSON, Kendall E. An introduction to numerical analysis. 1989.
-
IEEE754, https://fr.wikipedia.org/wiki/IEEE_754.
-
Wilkinson’s polynomial, sur wikipedia.